AI ML
MLOps in Production: Lessons from the Trenches
Real-world experiences deploying ML models at scale using AWS SageMaker and custom pipelines.
October 15, 2025
6 min read
By Lundi Zolisa Silolo
#MLOps#SageMaker#production#AWS#automation
MLOps in Production: Lessons from the Trenches
After deploying dozens of ML models in production, I've learned that the model is often the easy part. It's everything else that kills you.
The Reality Check
Academic ML: "Our model achieves 99.2% accuracy!"
Production ML: "Why did our model just recommend cat food to a dog owner?"
The gap between research and production is vast, and MLOps is the bridge.
Key Lessons Learned
Data Drift is Real and Ruthless
Your beautiful model trained on last year's data? It's probably garbage now. Implement monitoring for:
- Feature distribution changes
- Target variable shifts
- Correlation breakdowns
The Model Registry is Your Best Friend
Version everything:
- Model artifacts
- Training data snapshots
- Feature engineering code
- Hyperparameters
- Performance metrics
Automated Retraining is Non-Negotiable
Set up pipelines that:
- Detect performance degradation
- Trigger retraining automatically
- A/B test new models against current ones
- Roll back if things go wrong
The AWS SageMaker Experience
Working with SageMaker has taught me to think in terms of:
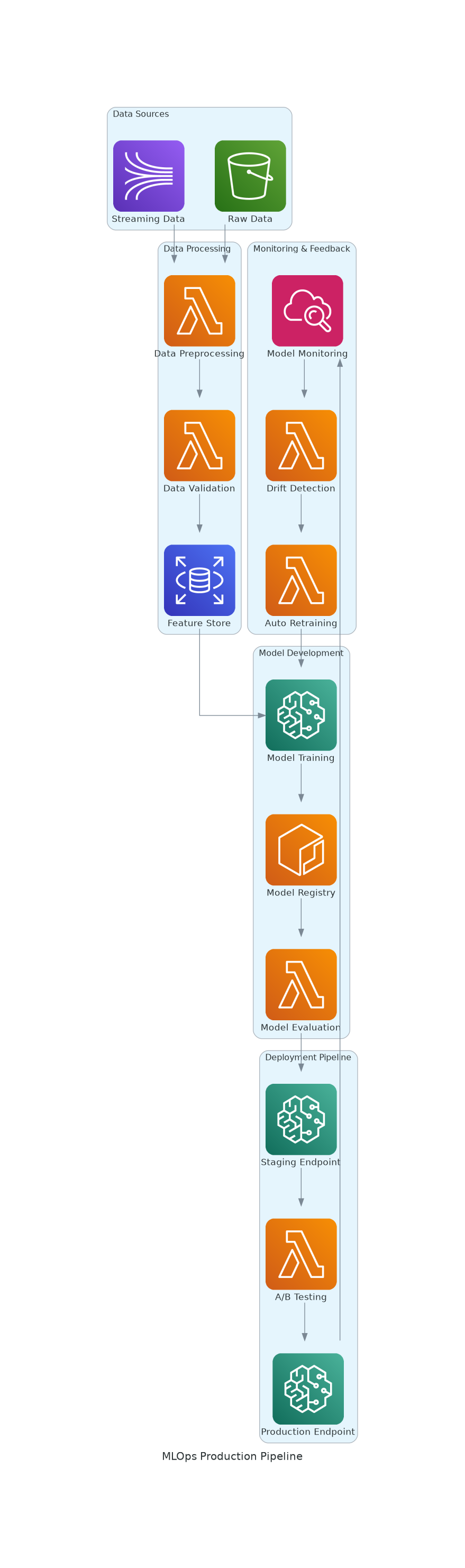
A complete MLOps pipeline from data sources to production monitoring
Pipelines, Not Scripts
Every ML workflow should be a pipeline:
`pythonfrom sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.steps import TrainingStep, ProcessingStep